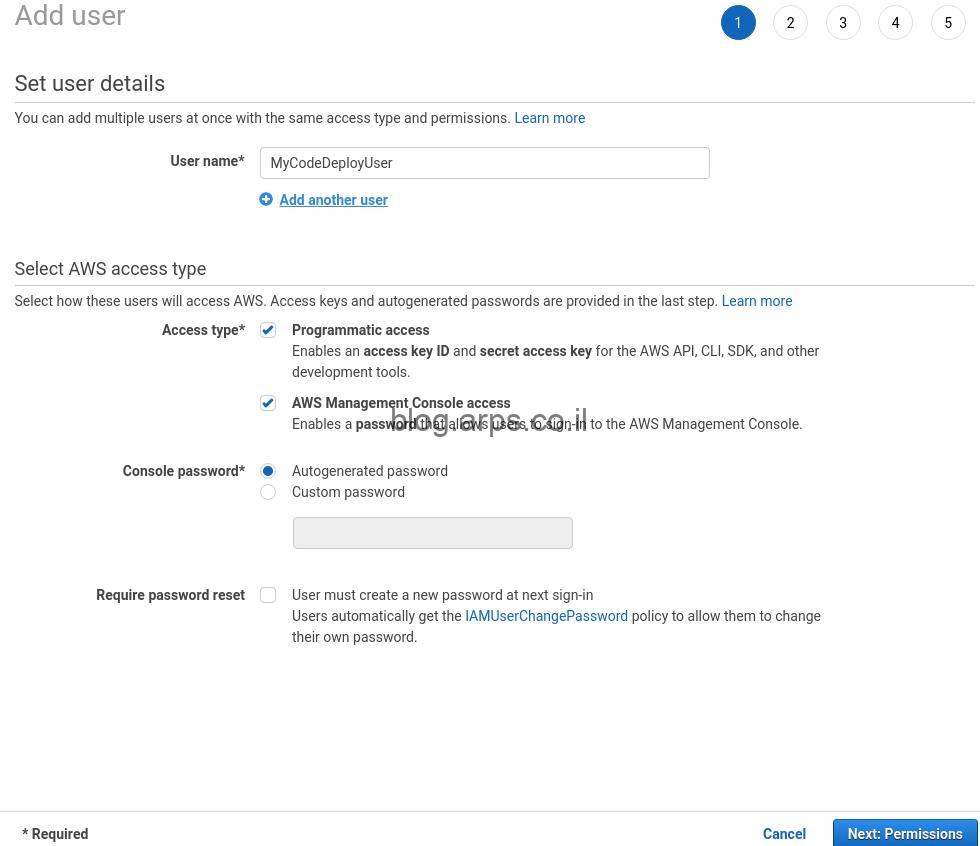
לשם ההדגמה נעבוד עם 3 מכונות וירטואליות, לראשון נקרא k8node1, לשני k8node2 ולשלישי שהוא ישמש כמסטר שלנו נקרא k8master.
3 המכונות האלו מריצות CentOs7.
את הפקודות הבאות נריץ בכל אחת מהמכונותם שלנו. הפקודה הראשונה תהיה
sudo su
על מנת לקבל הרשאות ROOT.
לשם ההדגמה , אנו נבטל את SELinux – שימו לב, לא לעשות את זה בפרודקשיין, זה בשביל להקל על ההדגמה בלבד.
setenforce 0
sed -i --follow-symlinks 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinuxבשלב הבא אנו נפעיל את br_netfilter כדי לאפשר תקשורת בין הקלסטרים שלנו, הפקודה בעצם מאפשרת לקוברנטיס לבצע שינויים בIPTABLES.
modprobe br_netfilter
echo '1' > /proc/sys/net/bridge/bridge-nf-call-iptablesבנוסף, אנו נבטל את הSWAP, הסיבה שאנו רוצים לעשות את זה היא על מנת שנקבל דיווח אמין על כמות הזיכרון שאנו משתמשים בו בפרודקשיין, כשאנו מאפשרים SWAP, הדיווח עלול להיות שגוי.
swapoff -aבנוסף, אנחנו צריכים לערוך את הקובץ fstab, כצעד ראשון נבצע "גיבוי" לקובץ המקורי על ידי הפקודה:
cp /etc/fstab /etc/fstab.orig
ואז נריץ את הפקודה
nano /etc/fstabונוסיף # לפני השורה הבאה:
/root/swap swap swap sw 0 0כך שנקבל את השורה הבאה במקום
#/root/swap swap swap sw 0 0עכשיו נתקין את החבילות הדרושות לדוקר
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum install -y docker-ce
בCENTOS אנו צריכים גם לוודא שדוקר וקוברנטיס ירוצו על אותו Cgroup Driver (הוא משמש לדיווח הסטטיסטיקה כמו זיכרון שאנו משתמשים בו וכו)
כמו כן, אנו נירצה שדוקר יופעל כל פעם שהמערכת מופעלת.
sed -i '/^ExecStart/ s/$/ --exec-opt native.cgroupdriver=systemd/' /usr/lib/systemd/system/docker.service
systemctl daemon-reload
systemctl enable docker --now
אחרי שסיימנו, נוספיף את הריפו של קוברנטיס על ידי הרצה של הפקודה הבאה:
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOFומייד לאחר מכן נתקין
yum install -y kubelet kubeadm kubectl
וכמובן לא נשכח להפעיל אותו
systemctl enable kubelet
systemctl start docker.service
שימו לב! את הפקודות הבאות נריץ רק בשרת המסטר שלנו
kubeadm init --pod-network-cidr=10.244.0.0/16
לאחר שנריץ את הפקודה הנל במסטר, נקבל בחזרה את הפקודה אותה נצטרך להריץ במכונות האחרות שלנו על מנת שהם יוכלו להצטרף לקלסטר שהמסטר שלנו מנהל, במיקרה שלי הפלט שהתקבל הוא:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.31.37.95:6443 --token 9mplpv.oxlntc0gz9iukdm3 \
--discovery-token-ca-cert-hash sha256:429959040fbf2743d9dc2ed67045548057ee2ae4781b5253143d8f93dca3bd0d והפקודה שחשוב שנשמור אותה היא למעשה הפקודה שמכילה את הטוקן שאנו צריכים כדי ששאר המכונות שלנו יוכלו להתחבר לקלסטר שיצרנו (למסטר)
kubeadm join 172.31.37.95:6443 --token 9mplpv.oxlntc0gz9iukdm3 \
--discovery-token-ca-cert-hash sha256:429959040fbf2743d9dc2ed67045548057ee2ae4781b5253143d8f93dca3bd0dלאחר שסיימנו נקיש exit כדי לצאת ממצב ROOT ונריץ את הפקודות הבאות:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/configבנוסף נעשה דפלוי לפנל שלנו:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
ונבדוק את הסטטוס של הקלסטר על ידי הפקודה
kubectl get pods --all-namespaces
את הפקודות הנל אנו צריכים להריץ בכל המכונות שלנו (למעט הפקודות שקשורות למסטר בלבד). לאחר מכן בכל מכונה שהיא לא המסטר נריץ את הפקודה שמכילה את הטוקן שלנו (במקרה שלי)
kubeadm join 172.31.37.95:6443 --token 9mplpv.oxlntc0gz9iukdm3 \
--discovery-token-ca-cert-hash sha256:429959040fbf2743d9dc2ed67045548057ee2ae4781b5253143d8f93dca3bd0d ולאחר מכן כשנריץ את הפקודה kubectk get nodes במסטר, אנו אמורים לראות את הנודים האחרים שלנו.